


Jul 22, 2026

Table Of Content
Claude Mythos Preview Signals a New Phase for AI in Vulnerability Research
What Is Claude Mythos Preview?
Why Is This a Significant Cybersecurity Development?
How Did Anthropic Test the Model?
What Types of Vulnerabilities Did It Find?
Why Are Technical Details Still Limited?
What Is Project Glasswing?
What Else Did Anthropic Share?
What Should Security Teams Take Away From This?
Related Articles

CVE-2026-50522 PoC Fuels SharePoint Attacks


CVE-2026-6875 Hits ServiceNow AI Platform
Jul 21, 2026

SonicWall SMA Flaws Lead to KNUCKLEBALL Malware
Jul 21, 2026


Apr 09, 2026
6 Mins Read
Jul 08, 2026

Claude Mythos Preview Signals a New Phase for AI in Vulnerability Research
Anthropic’s Claude Mythos Preview is drawing attention because it showed a much stronger ability to find and exploit software vulnerabilities than earlier models, including zero-day flaws in major operating systems, browsers, and open source codebases. Anthropic says the model’s performance was strong enough to justify a limited release through Project Glasswing, a program intended to help defenders secure critical software before similar capabilities become more widely accessible.
What Is Claude Mythos Preview?
Claude Mythos Preview is a new Anthropic model that the company says performed unusually well in cybersecurity testing. According to Anthropic, the model was not presented as a narrow offensive security tool. Instead, its cyber capability appears to come from broader improvements in reasoning, autonomy, and code-related tasks.
That matters because stronger general coding performance can also translate into stronger vulnerability research. A model that is better at understanding code, testing hypotheses, and working through complex tasks may also become better at identifying security flaws and building exploit paths.
Why Is This a Significant Cybersecurity Development?
What stands out here is not just that the model found bugs, but that it performed at a level that suggests AI-assisted vulnerability research is becoming much more practical. Anthropic says Mythos Preview was able to identify and exploit zero-day vulnerabilities in major platforms during testing, including browser targets and operating systems. That shifts the conversation from AI as a coding assistant to AI as a tool that can materially speed up offensive security research.
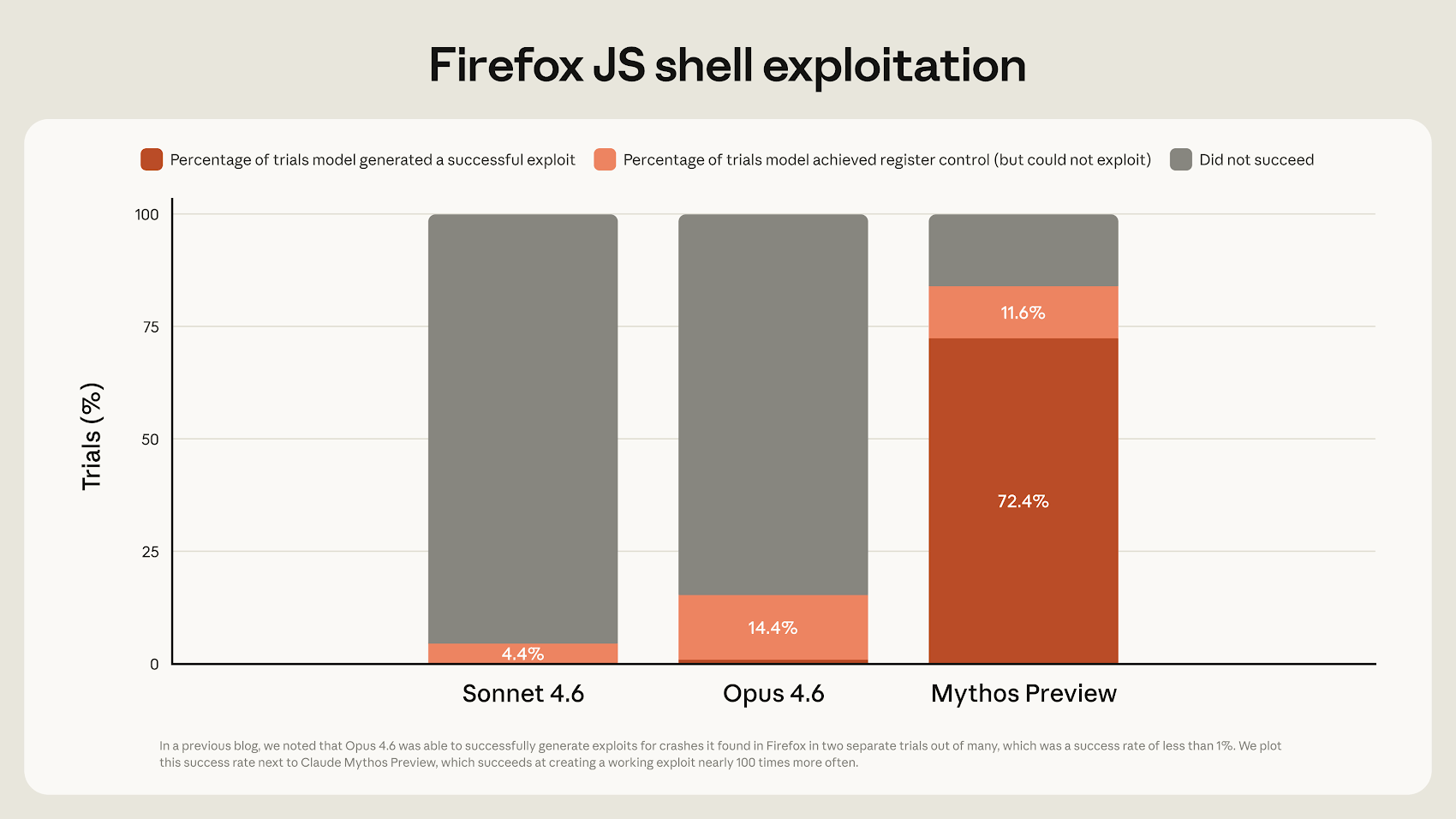
Claude Mythos Preview showed a much higher Firefox exploit success rate than earlier Claude models. (Source: Anthropic)
The capability jump also appears measurable. In Anthropic’s Firefox testing, Mythos Preview showed a much higher exploit success rate than earlier Claude models, suggesting this is not just a collection of isolated examples but part of a broader improvement in exploit generation performance.
How Did Anthropic Test the Model?
Anthropic says it focused on novel, real-world tasks, especially zero-day discovery, rather than relying only on older benchmarks. The reasoning is simple: if a bug was not previously known, the model cannot simply repeat memorized information. That makes zero-day discovery a more useful test of whether the model is actually reasoning through unfamiliar problems.
In Anthropic’s setup, the testing flow looked roughly like this:
- The model was given source code and a prompt to find a security vulnerability.
- It inspected the code and tested ideas inside isolated containers.
- It generated a bug report and proof-of-concept steps if successful.
- Anthropic used an additional review step to check whether the bug was real and worth pursuing.
This setup matters because it is closer to real vulnerability research than a traditional benchmark. It tests whether the model can work through unfamiliar problems rather than recall known ones.
What Types of Vulnerabilities Did It Find?
The write-up points mainly to memory safety issues, especially in C and C++ projects where these vulnerabilities are still common. Anthropic says the model found serious issues in multiple environments, including the OpenBSD bug, several Linux kernel privilege escalation chains, and CVE-2026-4747, a remote code execution vulnerability in FreeBSD’s NFS server that could allow an unauthenticated attacker to gain root access.
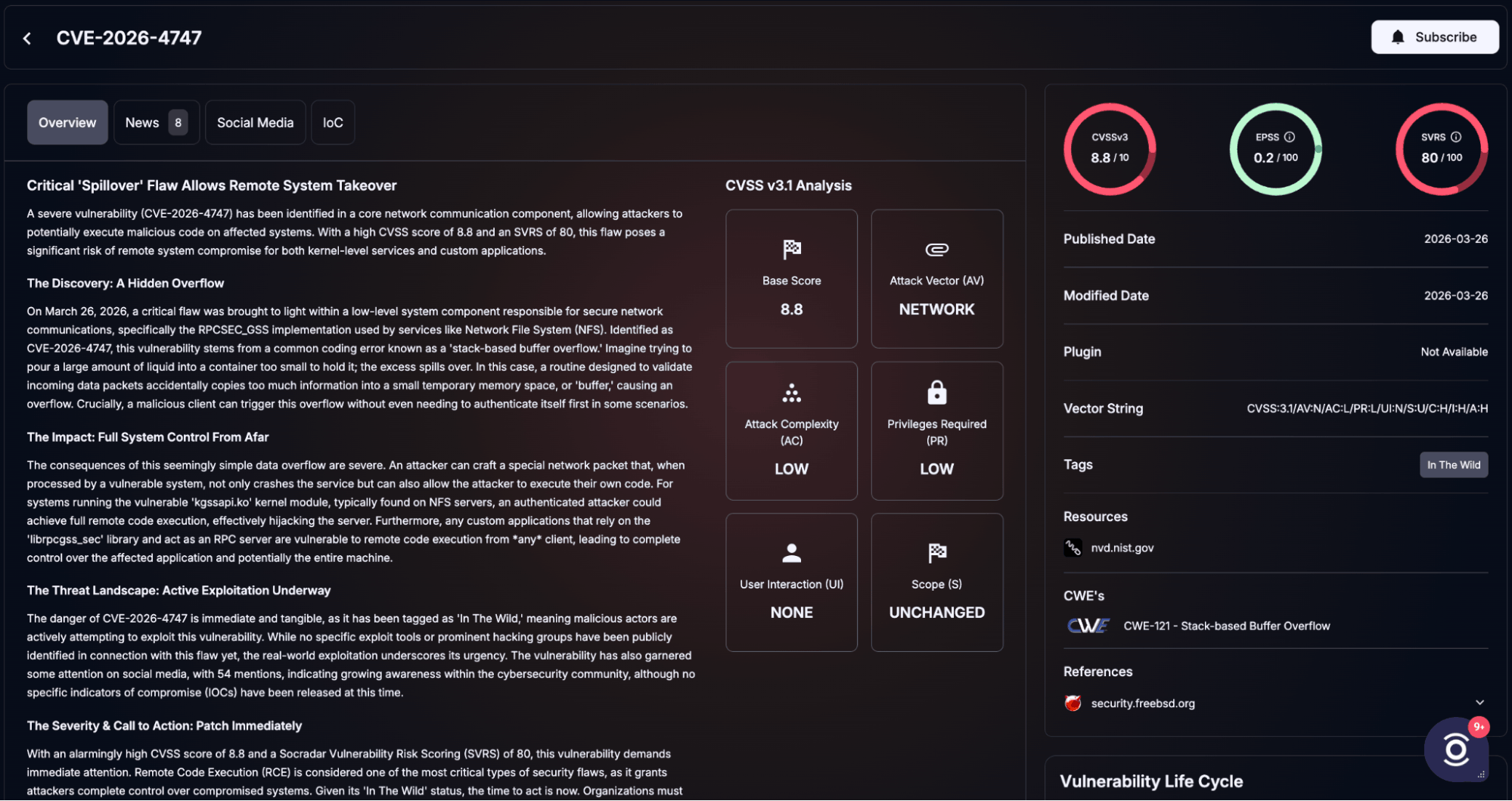
Details of CVE-2026-4747 (SOCRadar Vulnerability Intelligence)
In the Linux examples, the model reportedly chained together two, three, and sometimes four vulnerabilities to bypass protections such as KASLR and reach root access. Anthropic also says that in its internal testing corpus, Mythos Preview achieved full control flow hijack on ten separate fully patched targets, which marked a clear jump over earlier models.
Why Are Technical Details Still Limited?
Anthropic says most of the vulnerabilities it found are still unpatched. Because of that, the company has not shared detailed technical write-ups for most findings. Instead, it says it is following coordinated disclosure and discussing only a small number of cases that are already patched or safe to describe at a high level.
That means the public picture is still incomplete. The announcement gives a sense of the model’s capabilities, but not a full technical record of each finding. For defenders, the main point is not the missing exploit detail. It is that a model appears to be finding real, previously unknown vulnerabilities at a higher level than before.
What Is Project Glasswing?
Project Glasswing is Anthropic’s program for giving Mythos Preview to a limited set of critical industry partners and open source developers instead of releasing it broadly. The goal is to use the model to help secure important software before comparable capabilities become more common elsewhere.
Anthropic’s position is that these tools may strengthen defense over time, but the transition period could still be risky. That is especially true if highly capable models become easier to access before patching, triage, and disclosure workflows can keep up.
What Else Did Anthropic Share?
Beyond the examples highlighted in the main write-up, Anthropic also listed additional findings and proof-of-concept references across several categories, including:
- web browser exploit chains
- a vulnerability in a virtual machine monitor
- local privilege escalation exploits
- a smartphone lock screen bypass
- an operating system remote denial-of-service issue
- vulnerabilities in cryptography libraries
- a Linux kernel logic bug
Anthropic shared these as report and PoC identifiers rather than detailed public write-ups.
What Should Security Teams Take Away From This?
The clearest takeaway is that AI-assisted vulnerability research is becoming more practical and more capable. For security teams, that likely means more pressure in a few familiar areas:
- faster discovery of complex vulnerabilities
- quicker exploit development around known weaknesses
- more pressure on patching and exposure management
- greater urgency around triage and asset visibility
This is especially relevant for high-value systems, older codebases, and software written in memory-unsafe languages. As models improve, the gap between vulnerability discovery and defensive response may shrink. Teams that already struggle with patch backlogs, asset visibility, or triage speed are likely to feel that pressure first.

