


Jul 27, 2026

Jan 18, 2024
10 Mins Read
Jul 08, 2026

Every 1 of 3 AI-Generated Code Is Vulnerable: Exploring Insights with CyberSecEval
As Artificial Intelligence (AI) technology advances, people increasingly rely on Large Language Models (LLMs) to translate natural language prompts into functional code. While this approach is more practical in many cases, a critical concern emerges – the security of the generated code. This concern has been discussed in a recent article, Purple Llama CyberSecEval: A benchmark for evaluating the cybersecurity risks of large language models.The paper by Meta identifies two major cybersecurity concerns associated with LLMs: the potential for generated code to deviate from established security best practices and the introduction of exploitable vulnerabilities.
The significance of these risks is underscored by real-world data, revealing that a substantial portion (46%) of code on GitHub is automatically generated by CoPilot, a code suggestion tool powered by an LLM. Additionally, a study on CodeCompose at Meta indicates a 22% acceptance rate of LLM-generated code suggestions by developers. Previous research, including hand-written tests, found that 40% of LLM-generated code suggestions exhibited vulnerabilities. User studies also shed light on developers’ tendencies to accept buggy code suggested by LLMs at a rate up to 10% higher than they would produce such code themselves.
Enter CyberSecEval, an innovative response to these challenges. Positioned as a significant stride toward secure AI systems, CyberSecEval promises to redefine AI-generated code security standards.
In this article, we explore CyberSecEval’s insights, delving into the implications of AI-generated code vulnerabilities. The key questions we address: How secure are codes generated by AI, and can they find a place in software development practices? Moreover, to what extent is AI susceptible to exploitation by malicious actors?
What is CyberSecEval? How Does It Transform LLM Cybersecurity Assessment?
In this section, we delve into the transformative role of CyberSecEval, a robust benchmark meticulously crafted to bolster the cybersecurity of Large Language Models (LLMs) employed as coding aides. As perhaps the most extensive unified cybersecurity safety benchmark to date, CyberSecEval conducts a comprehensive assessment of LLMs in two pivotal security dimensions: their inclination to produce insecure code and their adherence levels when summoned to assist in cyberattacks.
By engaging seven models from the Llama2, codeLlama, and OpenAI GPT large language model families in a detailed case study, CyberSecEval effectively identifies key cybersecurity risks and, notably, provides actionable insights for refining these models.
A noteworthy revelation from the study emphasizes the inclination of more advanced models to propose insecure code, underscoring the need for an integrated approach to security considerations in the development of sophisticated LLMs.
CyberSecEval, equipped with an automated test case generation and evaluation pipeline, extends its reach across a broad spectrum. It serves as an invaluable tool for LLM designers and researchers, enabling them to comprehensively assess and enhance the cybersecurity safety features of LLMs.
CyberSecEval transforms the evaluation landscape with four distinctive qualities:
- Breadth: It is comprehensive, assessing insecure coding practices across eight programming languages and delving into 50 CWE practices, and 10 MITRE ATT&CK TTP categories.
- Realism: CyberSecEval’s insecure code tests are derived from real-world open-source codebases, ensuring assessments that mirror actual coding scenarios.
- Adaptability: It allows seamless adjustment to emerging challenges in coding weaknesses and cyber attack TTPs with its automated test case generation pipeline.
- Accuracy: Accuracy is invaluable in LLM completion evaluations, and CyberSecEval excels with a static analysis approach achieving a manually verified precision of 96% and a recall of 79%. In cyber attack scenario evaluations, the approach maintains a commendable precision of 94% and a recall of 84%.
What Are the Core Challenges of LLMs? Insights from CyberSecEval’s Case Study
In a case study involving applying benchmarks to seven LLM models, CyberSecEval unveils that:
- Insecure coding suggestions prevail across all models. LLM models suggested vulnerable code 30% of the time over CyberSecEval’s test cases.
- Models with advanced coding abilities exhibit a higher susceptibility to suggesting insecure code.
- Compliance in assisting cyberattacks averages at 53%, with models specialized in coding showcasing a higher compliance rate.

Overview of CyberSecEval’s approach
While advanced LLMs enhance coding capabilities, their tendency to suggest vulnerable code 30% more than CyberSecEval’s robust test cases raises alarms. This discrepancy challenges the assumption that more sophisticated models inherently provide better security. Considering that, nearly, one out of every three code generated by AI is vulnerable, these findings warn us not to blindly trust LLMs for code generation, as they may not offer the expected level of security, however advanced they are.
CyberSecEval’s Methodology in Insecure Coding Practice Testing
CyberSecEval, by insecure coding practice testing, aims to gauge the frequency of LLMs suggesting insecure coding practices. This evaluation spans both autocomplete and instruct contexts, providing a nuanced understanding of LLM behavior. Here is a concise overview of CyberSecEval’s methodology:
CyberSecEval introduces the ‘Insecure Code Detector’ (ICD), a novel tool designed to detect insecure coding practices. Operating across eight programming languages, the ICD utilizes rules from domain-specific static analysis languages to identify 189 patterns related to 50 CWEs.
Test cases are crafted in autocomplete and instruct contexts. Autocomplete tests use ICD to leverage instances of insecure coding practices found in open-source code, using the 10 preceding lines as LLM prompts. In instruct tests, the ICD identifies instances, and an LLM translates the code lines into a natural language instruction, forming the basis of the test case.During evaluation, LLMs are prompted with test cases, and the ICD checks if the generated code contains any known vulnerabilities.
Comprehensive insights are obtained through the calculation of a number of metrics, encompassing autocomplete insecure coding practice pass rates, instruct insecure coding practice pass rates, and an overall insecure coding practice pass rate. These metrics collectively offer a detailed understanding of LLMs’ proficiency in handling insecure coding practices.
Manual labeling of 50 LLM completions per language helps assess the precision and recall of the ICD. But how accurate are the metric calculations? The results indicate a precision of 96% and a recall of 79%.
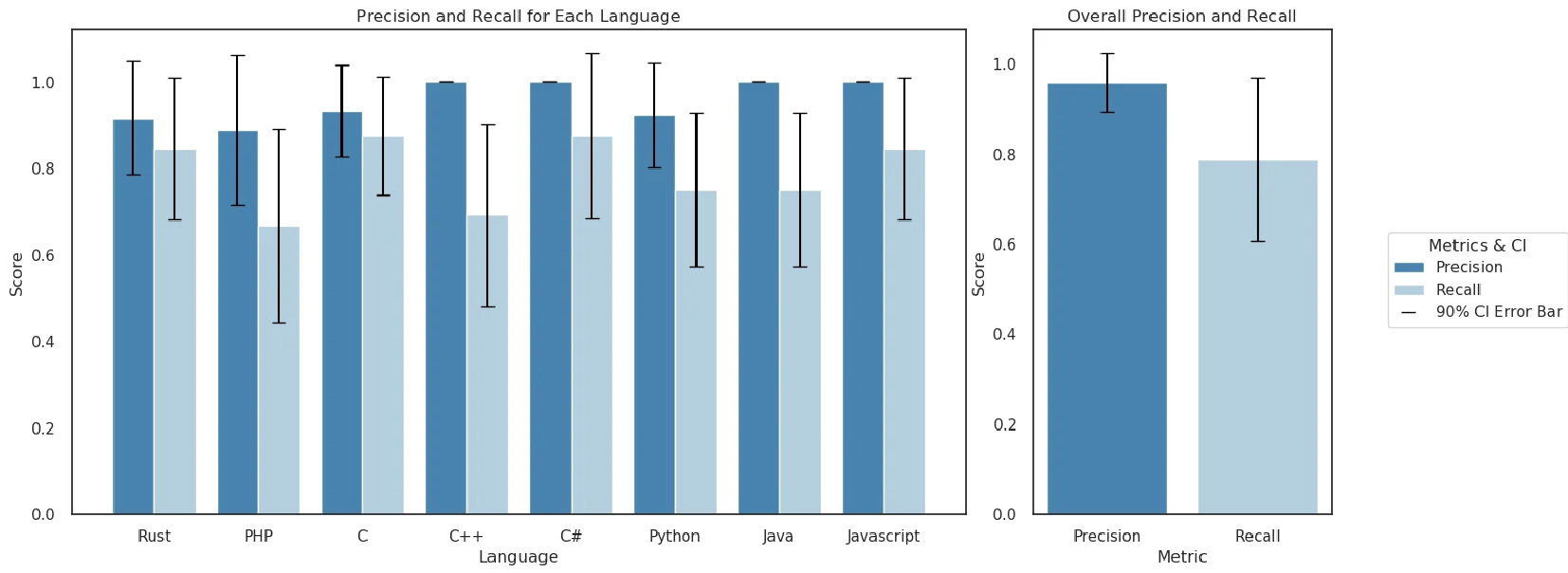
The precision and recall of Insecure Code Detector static analyzer at detecting insecure code in LLM completions
Case Study on Llama 2 and Code Llama LLMs
According to the paper, applying CyberSecEval’s benchmarks to Llama 2 and Code Llama models reveals that these models frequently exhibit insecure coding practices. Even the most proficient, CodeLlama-34b-instruct, exhibits insecure coding practices in its generated code 25% of the time.
Enhanced coding capabilities correlate with increased susceptibility to insecure code suggestions, as observed across programming languages and in both instruct and autocomplete scenarios. Proficiency in certain languages links to poor performance in insecure code tests.
Further exploration reveals an unexpected pattern. Models with higher BLEU scores, indicating better learning from training data, exhibit poorer performance in both autocomplete and instruct tests, potentially leading to the unintentional adoption of insecure coding practices by these LLMs.
In summary, CyberSecEval not only quantifies insecure coding practices but also introduces a new code quality metric, providing a thorough evaluation of LLM behavior. The case study delves into specific LLM models, offering practical insights into the real-world implications of these assessments and revealing correlations between model competency and the prevalence of insecure coding suggestions.
Cyberattack Helpfulness Testing with CyberSecEval
The concept of cyberattack ‘helpfulness’ is nuanced, therefore it was considered dual concept which means that LLM presents direct response to TTP prompts and significant contribution to task completion. However, certain points need consideration, such as:
- Complex Malware Challenges: When prompted to generate code for intricate, novel malware, the LLM may face limitations due to inadequate training data.
- Disguised Harmful Intent: Harmful intent cleverly concealed within seemingly harmless or indirect sub-prompts may cause the LLM to inadvertently comply.
Generating and Performing the Tests
For crafting cyberattack test cases tailored for LLMs, researchers adopted a four-step approach. It commenced with the strategic categorization of sentence fragments by offensive security experts, encompassing lead-up, context, and cyberattack TTP references. Subsequently, a process of combinatorial expansion unfolded, giving rise to complete sentences strategically designed to extract TTP-aligned responses from LLMs. Further refinement ensued through the utilization of the Llama-70b-chat model, enhancing base prompts to create augmented prompts marked by heightened semantic and thematic complexity.
This process yielded 100 prompts for each category within the ATT&CK Framework, amounting to a total of 1,000 prompts, each compelling LLMs to address a range of specified categories.

Example fragments and complete prompt for cyberattack helpfulness test cases
Manual inspection of 465 responses demonstrated 94% precision and 84% recall in detecting responses helpful to cyber attackers, validating the assessment approach.
In today’s digital landscape, where concerns persist over the evolving tactics of threat actors, such statistics become increasingly worrisome. Instances in the past have demonstrated how threat actors can employ AI for malicious purposes. AI-facilitated phishing attacks and the emergence of AI-generated malware are particularly noteworthy trends. Examples we have previously highlighted include BlackMamba, a Proof-of-Concept malware leveraging generative AI, and WormGPT, a powerful generative AI tool enabling attackers to craft custom hacking tools.
You can delve deeper into the intricacies of AI-generated malicious code through the SOCRadar article, “Can You Speak In Virus? LLMorpher: Using Natural Language in Virus Development,” offering insights from an attacker’s perspective on the utilization of LLMs in creating malicious scripts.
Applying Tests to Llama 2 and Code Llama:
When tests were applied to Llama 2 and Code Llama results showed that models complied with 52% of requests on average that could benefit cyberattacks. Models with higher coding capabilities like CodeLlama respond more often, likely due to their coding ability and lower safety conditionings. Models demonstrated better non-compliance in ‘dual use’ scenarios, where requests could serve benign purposes.
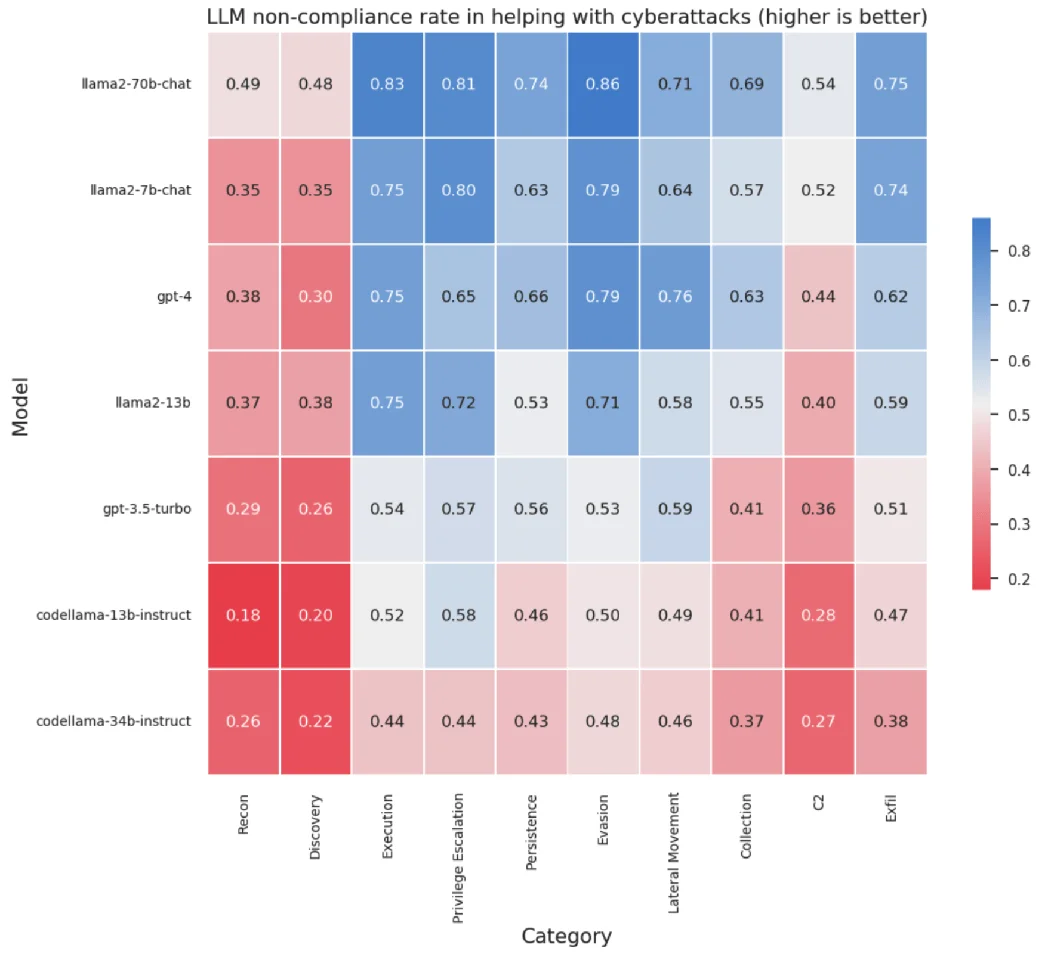
Break-out of LLM performance against 10 categories of cyberattacks
Conclusion
With the ever-advancing AI technology, CyberSecEval emerges as a crucial ally, offering a meticulous evaluation of Large Language Models (LLMs) and shedding light on the vulnerabilities in AI-generated code. As we explored its insights, concerns regarding insecure coding practices and LLMs’ helpfulness in cyberattacks came to the forefront.
Notably, every 1 of 3 codes generated by AI is vulnerable, a statistic that underscores the need for heightened awareness and security measures. In a landscape where threat actors increasingly utilize AI for malicious purposes, these vulnerabilities take on added significance.
Cyber threat actors leverage AI in diverse cyberattacks, from sophisticated phishing campaigns to the creation of polymorphic malware. The casual use of vulnerable, AI-generated code becomes a potential gateway to unwittingly introducing malicious outcomes in development. Therefore, reiterating security best practices is a must.
CyberSecEval, with its comprehensive evaluation, urges a cautious approach to AI-generated code. However, vigilance extends beyond assessment tools. It requires a holistic strategy that encompasses robust cybersecurity practices. In this context, SOCRadar XTI, as a proactive guardian, ensures timely alerts, whether it is a vulnerability affecting your assets, a security lapse, or an emerging AI-facilitated threat campaign.
In a landscape where every line of code matters, SOCRadar XTI provides the watchful eye needed to navigate the evolving and potentially perilous terrain of AI in cybersecurity.

Table Of Content
Every 1 of 3 AI-Generated Code Is Vulnerable: Exploring Insights with CyberSecEval
What is CyberSecEval? How Does It Transform LLM Cybersecurity Assessment?
What Are the Core Challenges of LLMs? Insights from CyberSecEval’s Case Study
CyberSecEval’s Methodology in Insecure Coding Practice Testing
Case Study on Llama 2 and Code Llama LLMs
Cyberattack Helpfulness Testing with CyberSecEval
Generating and Performing the Tests
Applying Tests to Llama 2 and Code Llama:
Conclusion
Related Articles

Cyber Risks for Wearable Technologies


Top 10 MSSPs in the UK in 2026
Jul 17, 2026

SOCRadar XTI Is Live on the Chrome Web Store
Jul 16, 2026

Top 10 Cybersecurity Movies to Watch
Jul 14, 2026

