



























Apr 30, 2025

Llama Guard: A Potent Ally for Threat Detection in LLM Environments
In a previous article, we delved into CyberSecEval, a benchmark created by Meta to tackle primary security concerns surrounding Large Language Models (LLMs). These concerns include the potential for generated code to diverge from established security best practices and the introduction of exploitable vulnerabilities. In this blog post, we will take a step further and explore a comprehensive middleware called Llama Guard, as well as its potential usage in cyber threat detection.
Llama Guard is a revolutionary middle-layer model designed to fortify existing API-based safeguards, offering additional defense against the influx of malicious or nonsensical requests.
At its core, Llama Guard serves as a robust filtration system, providing organizations with the means to enhance the efficiency of their AI models. Acting as a guard between users and the underlying language model, Llama Guard introduces an extra layer of protection by classifying content as safe or unsafe based on a user-defined taxonomy and harm types.
Consider the scenario where a user attempts to generate malware using an AI model. Leveraging Llama Guard, organizations can proactively identify and eliminate such malicious requests, preventing potential cybersecurity threats before they have the chance to inflict harm.
This article explores the application of Llama Guard in threat detection, examining its capabilities to filter and classify user inputs and model responses to identify unsafe content.
What is Llama Guard?
Llama Guard emerges as a high-performance model strategically positioned to fortify AI-based content moderation, functioning as a crucial middle-layer model. Rooted in the robust architecture of Llama2-7b, this innovative safeguard is designed to discern safety and potential harm within user inputs and language model responses. Positioned as a gatekeeper, Llama Guard implements an additional layer of scrutiny to filter out unsafe content and mitigate potential risks.
Operating seamlessly with existing AI models, it provides an extra line of defense without the need for exhaustive modifications. Llama Guard’s adaptability allows organizations to harness its capabilities as an augmentation to their existing AI infrastructure.
Llama Guard’s Configurability and Practical Application in Threat Detection
Llama Guard’s flexibility shines through its user-configurable settings. While predefined categories encompass violence, sexual content, guns, controlled substances, suicide, and criminal planning, organizations can tailor these definitions to align with their unique requirements. This adaptability empowers users to create a customized defense mechanism that suits their specific threat landscape.

Example task instructions for the Llama Guard prompt and response classification tasks. (Source)
Like the previously mentioned example, organizations can employ it in scenarios where a user attempts to use an LLM to create malware. Further examples could include combating the now-common AI-generated phishing schemes and threat actors’ attempts to use LLMs as a Command and Control infrastructure. Because Llama Guard is highly configurable, its usability extends to various scenarios.
In our CyberSecEval article, we mentioned the security challenges arising from LLMs’ tendency to assist cyberattacks. Meta’s manual inspection of 465 responses revealed worrisome statistics: 94% precision and 84% recall in detecting responses aiding cyber attackers. Past instances highlight AI’s malicious use in phishing attacks and AI-generated malware. Examples include BlackMamba, a Proof-of-Concept malware leveraging generative AI, and WormGPT, a potent tool enabling attackers to craft custom hacking tools.
Llama Guard, essentially, acts as a defense against LLMs’ involvement in such tools and cyberattacks, providing customizable protection against evolving cyber threats.
You can also delve deeper into AI-generated malicious code in our article, “Can You Speak In Virus? LLMorpher: Using Natural Language in Virus Development,” providing insights from an attacker’s perspective.
Elements That Form Llama Guard: Precision, Adaptability, and the Future of LLM Security
Llama Guard, a robust middle-layer model, is constructed on a foundation of meticulous guidelines, adaptive prompting techniques, and a carefully curated dataset. Learn more about its building method below:
Guidelines as the Building Blocks
At its core, Llama Guard relies on a comprehensive set of guidelines. These guidelines serve as the model’s lens, delineating numbered categories of violation, along with plain text descriptions that define what is safe and unsafe for each category. The model’s safety assessments are confined to these specified categories and their corresponding descriptions, ensuring a targeted and precise approach.
Adaptability through Zero-shot and Few-shot Prompting
Adaptability is the hallmark of Llama Guard, especially when the guidelines it was trained on differ from those of the target domain. Zero-shot and few-shot prompting are the dynamic tools enabling flexibility.
In zero-shot prompting, the model interprets either category names or names with descriptions during inference, aligning itself with the target domain’s guidelines.
Few-shot prompting, a more robust strategy, incorporates 2 to 4 examples for each category. Meta notes that learning occurs in-context, and the examples are not used for training the model.
Data Collection for Precision
Anthropic’s human preference data serves as a guide during training. An in-house red team meticulously annotates a dataset of 13,997 prompts and responses based on the predefined taxonomy.
This annotation includes prompt-category, response-category, prompt-label (safe or unsafe), and response-label (safe or unsafe). A rigorous cleaning process ensures data integrity, and a 3:1 random split between fine-tuning and evaluation further refines the model’s capabilities.
In short, Llama Guard forms from careful guidelines, dynamic prompting, and a carefully curated dataset, demonstrating Meta’s commitment to precision and adaptability. This precision and adaptability could be used to detect threats, thereby improving the security of LLMs used in business contexts.
Llama Guard’s Evaluation
Llama Guard faces model taxonomy challenges in experiments, prompting evaluation based on in-domain performance and adaptability to diverse taxonomies. The assessment employs three techniques: overall binary classification, per-category binary classification via 1-vs-all, and per-category binary classification via 1-vs-benign. The latter, albeit potentially optimistic, proves valuable for off-policy evaluations of baseline APIs.
Evaluation on Public Benchmarks
Ensuring fairness, Llama Guard aligns with the taxonomies of ToxicChat and the OpenAI Moderation Evaluation Dataset during experimental assessments. ToxicChat, with 10,000 samples, mirrors real-world user-AI interactions, employing a strict majority vote for binary toxicity. In parallel, aligned with the OpenAI moderation API taxonomy, each example is flagged for violations in specific risk categories.
Probability Score-Based Baselines
OpenAI Moderation API, a GPT-based classifier, assesses text across eleven safety categories, providing probability scores and binary labels. Perspective API, designed for online platforms, leverages machine learning to identify and eliminate toxicity, threats, and other offensive content in comments and discussions.
Example Use Cases of Llama Guard for Cyber Threat Detection
Upon completing the submission form on its HuggingFace page, you can receive a token to initiate testing with the Llama Guard model. We conducted our testing of the model’s capabilities in the cyber threat detection context by employing a ready notebook on Google Colab.
We devised a taxonomy that encompasses criteria related to malware, unauthorized access, data breaches, social engineering schemes, DoS attacks, and various intrusion methods. Our aim is for prompts related to these criteria to be effectively filtered through Llama Guard, responding with the ‘unsafe’ label to requests exhibiting malicious intent.

Taxonomy of unsafe categories regarding cyber threats
As demonstrated in the example below, when the content is deemed safe, the model responds with a single-word answer: ‘safe.’ Conversely, if the content is identified as unsafe, the model replies accordingly and specifies its category according to the set taxonomy.

A safe user input
Llama Guard is designed to monitor responses generated by a conversational LLM throughout interactions with users. Upon the completion of a conversation with the LLM’s turn, Llama Guard can also conduct content moderation on its output, adhering to the established taxonomy.

An unsafe request aligning with the first category in our taxonomy
Let’s also test if Llama Guard can distinguish a genuine cyber threat in a post or message by a threat actor. We added a new section into our taxonomy for such scenarios, outlining that if a message suggests explicit threats to organizations, individuals, or nations, or involves planning or carrying out a cyberattack, it should be labeled ‘unsafe.’ On the other hand, if the content is just a general discussion or shares helpful safety information about other threats, it should be considered ‘safe.’

Addition to the taxonomy
We used a part of a message from a threat actor’s Telegram channel for this example. The message discussed targeting France and threatened to disrupt its infrastructure. Here is the result:

The threat actor’s message is marked as unsafe, falling under the 7th category in our taxonomy
From malicious software queries to explicit threats and cyberattack planning, Llama Guard excels at content moderation. In every scenario we provided as an example, the model demonstrated its effectiveness by accurately identifying potential threats and labeling prompts as unsafe.
Llama Guard’s ability to adapt to different taxonomies makes it a powerful instrument for improving user safety and ensuring secure interactions with conversational language models. In the next section, we will further explore its adaption capability.
Fine-Tuning Llama Guard: Adapting to New Taxonomies
Exploring Llama Guard’s adaptability to different taxonomies, Meta has conducted fine-tuning experiments on the ToxicChat dataset, which we mentioned in the section titled “Llama Guard’s Evaluation.” ToxicChat specifically focuses on identifying violations in content generated by LLMs based on user prompts and their generations from GPT-4 and Vicuna.
Fine-tuning is executed using varying percentages (10%, 20%, 50%, 100%) of the ToxicChat training data, revealing its effectiveness in enhancing model performance for specific tasks, and whether it contributes positively. Comparative analysis against Llama2-7b, fine-tuned in an identical setup, provides valuable insights:
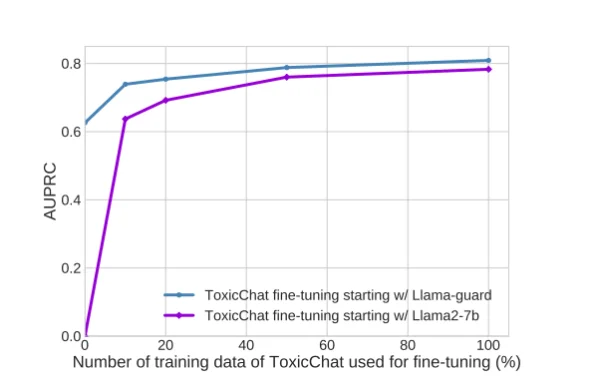
Adapting Llama Guard and Llama2-7b to ToxicChat via further fine-tuning, Llama Guard shows better adaptability to ToxicChat taxonomy than Llama2-7b
Results indicate that fine-tuning on a different taxonomy significantly accelerates Llama Guard’s adaptation to new taxonomies. Llama Guard achieves comparable performance with Llama2-7b, trained on 100% of the ToxicChat dataset, using only 20% of the data. Moreover, when trained with the same amount of data, Llama Guard surpasses the performance of Llama2-7b.
Overall, Llama Guard’s exceptional adaptability is evident as it competes closely with OpenAI’s API on the OpenAI Mod dataset, even without specific training. Impressively, it outshines other methods on the ToxicChat dataset.
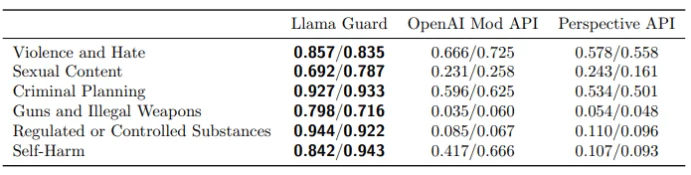
The table provides a breakdown of prompt/response classification performance, affirming Llama Guard’s competence across safety categories in both classifications. (Source)
Conclusion
In conclusion, Llama Guard can be a pivotal defender in the realm of AI security, bridging the gap between users and Large Language Models (LLMs). Crafted meticulously on a foundation of thoughtful guidelines, dynamic prompting, and precision-focused data collection, Llama Guard embodies Meta’s commitment to precision and adaptability.
The model’s robustness is highlighted in its adaptability through zero-shot and few-shot prompting, offering a flexible defense against diverse guidelines in target domains. With precision at its core, Llama Guard’s adherence to user-defined taxonomies ensures a targeted approach, swiftly categorizing content as safe or unsafe.
The versatility of Llama Guard extends beyond its foundational elements. In evaluations, it showcases remarkable adaptability, competing closely with established APIs even without specific training. Its fine-tuning capability further accelerates adaptation to new taxonomies, demonstrating superior performance with minimal data compared to its counterparts.
The true strength of Llama Guard emerges in its application for threat detection. Organizations, in particular, stand to benefit significantly from Llama Guard’s configurability and practical application in threat detection. Its seamless integration with existing AI models ensures an additional layer of defense without exhaustive modifications.
Acting as a vigilant gatekeeper, it can proactively identify and eliminate malicious requests, safeguarding against cybersecurity threats. Whether thwarting AI-generated phishing schemes, combatting malware creation attempts, or countering other various malicious use of LLMs, Llama Guard offers a customizable and robust defense mechanism.
In a landscape where AI-facilitated cyber threats are on the rise, Llama Guard emerges as a crucial ally, enhancing the security posture of LLMs in business scenarios.
As the digital landscape evolves, Llama Guard exemplifies yet another shift in AI security, where precision, adaptability, and proactive threat detection converge to fortify organizations against emerging cyber risks. It paves the way for a future where AI models can operate with heightened security, fostering trust and reliability in the ever-expanding realm of artificial intelligence.

Related Articles


Verizon 2025 DBIR: 10 Takeaways You Should Know
Apr 29, 2025

Everything You Need to Know About TIBER-EU Framework
Apr 29, 2025


Subscribe to our newsletter and stay updated on the latest insights!