


Mar 10, 2026

Mar 10, 2026
3 Mins Read
Apr 21, 2026
Table Of Content
Related Articles

SMS Bombing

Dark Web Monitoring
Feb 19, 2026

Dark Web
Jan 31, 2026

Threat Actors
Jan 08, 2026

Ransomware
Jan 31, 2026

What is Data Lake?
A data lake represents a centralized repository architecture designed to store vast amounts of raw data in its native format. Unlike traditional data warehouses that require structured data with predefined schemas, a data lake accepts structured, semi-structured, and unstructured data from multiple sources without requiring upfront transformation or organization.
This flexible storage approach allows organizations to capture everything from database records and log files to social media feeds, IoT sensor data, and multimedia content. The term “lake” aptly describes this concept—just as a natural lake collects water from various tributaries, a data lake aggregates diverse data streams into a single, scalable storage environment.
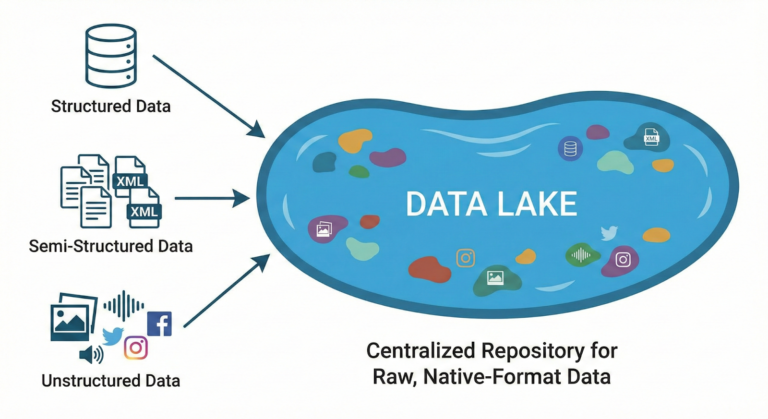
How Data Lakes Function
Data lakes operate on a “schema-on-read” principle, meaning data structure and organization occur when information is accessed rather than when it’s stored. This approach contrasts sharply with traditional “schema-on-write” systems that require data formatting before storage.
The architecture typically consists of three primary layers: the storage layer (often cloud-based object storage), the processing layer (utilizing frameworks like Apache Spark or Hadoop), and the consumption layer where analytics tools and applications access processed information.
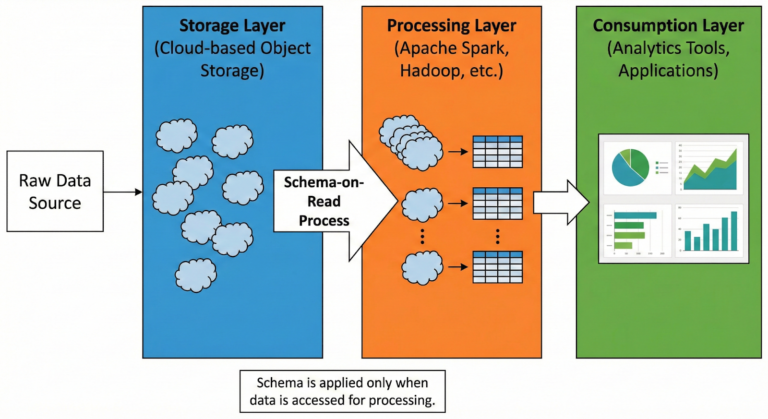
Modern data lake implementations leverage cloud platforms such as Amazon S3, Azure Data Lake Storage, or Google Cloud Storage, providing virtually unlimited scalability and cost-effective storage solutions.
Types and Real-World Applications
Enterprise Data Lakes
Large corporations implement comprehensive data lakes to consolidate customer information, transaction records, supply chain data, and operational metrics. Netflix, for example, uses its data lake to analyze viewing patterns, content performance, and user preferences across millions of subscribers.
Cloud-Native Data Lakes
Organizations increasingly adopt cloud-native solutions that offer managed services, automated scaling, and integrated security features. These implementations reduce infrastructure complexity while maintaining data accessibility.
Departmental Data Lakes
Smaller, focused implementations serve specific business units, such as marketing teams analyzing customer engagement data or manufacturing departments monitoring equipment performance metrics.
Strategic Importance in Modern Business
Data lakes have become critical infrastructure for organizations pursuing data-driven decision-making strategies. They enable advanced analytics capabilities, including machine learning model training, predictive analytics, and real-time business intelligence.
The flexibility of a data lake supports agile business requirements, allowing companies to store data today for use cases that may emerge tomorrow. This approach proves particularly valuable in industries experiencing rapid digital transformation or regulatory changes requiring comprehensive data retention.
Implementation Best Practices
Successful data lake deployment requires careful governance strategies to prevent creating “data swamps”—repositories where information becomes difficult to locate or use effectively.
Essential practices include implementing robust metadata management systems, establishing clear data quality standards, and maintaining comprehensive data catalogs. Security measures must encompass encryption, access controls, and audit trails to protect sensitive information.
Organizations should also establish data lifecycle policies defining retention periods, archival procedures, and deletion schedules to maintain optimal performance and compliance with privacy regulations.
Regular monitoring and optimization ensure the data lake continues serving evolving business needs while controlling storage costs and maintaining system performance across growing data volumes.










