



Jul 29, 2026

May 21, 2026
4 Mins Read

How Dark Data Leaves Security Teams One Step Behind
Cyber Threat Intelligence has come a long way. In the past, real-time threat feeds, dark web monitoring, and indicator-sharing platforms were reserved for governments and Fortune 500 companies. Today, 90% of organizations have dedicated CTI resources, according to the 2026 SANS CTI Survey. The tools are better. The data is richer. Access is no longer the bottleneck, but 42% of security alerts go uninvestigated.
Breaches keep climbing. Attacks move faster. Response times lag behind. If the intelligence is there and the tools work, what’s going wrong?
The gap between knowing and doing
The answer isn’t about intelligence quality. Security teams are drowning in data they can’t process fast enough. The answer is about what happens after the intelligence arrives.
The 2026 SANS survey shows that 62% of CTI teams operate with fewer than four full-time analysts. Team sizes have stayed flat since SANS started tracking them in 2024, even as the scope of CTI work, executive expectations, and integration demands have grown steadily.
The result: alerts pile up, tasks carry over between shifts, and analysts spend their days triaging and re-triaging instead of investigating with any depth. The bottleneck has shifted from “we don’t know enough” to “we can’t process what we already know.”
We call this unprocessed intelligence dark data: the growing volume of threat intelligence that gets collected, delivered, paid for, and then never acted on.
How big is the problem?
We can look at the numbers and the clear picture they paint:
- 42% of security alerts go uninvestigated due to capacity constraints alone (Microsoft/Omdia, 2025)
- 67% of daily alerts can’t be addressed by analysts (Vectra AI, 2023)
- 97% of analysts worry about missing a real threat buried in the noise
- 2.7 hours per day are spent on manual triage, mostly sorting through false positives and duplicates
This backlog doesn’t reset. Each shift starts behind, working through what the previous shift couldn’t finish. Over days and weeks, a compounding shadow of intelligence builds up.
Dark data has real consequences
The worst side is that this is not an abstract efficiency problem that stays at a distance. Many major breaches had warning signs sitting in the data:
- Target (2013): FireEye flagged the malware. The alert was missed among thousands of others. Cost: $200M+, 40 million payment cards exposed.
- Equifax (2017): A critical Apache Struts vulnerability (CVSS 10.0) was flagged by US-CERT. The patch was never applied. Attackers had 76 days of access. 143 million consumers compromised.
- Suffolk County (2022): Palo Alto Cortex fired multiple malware alerts before a BlackCat ransomware attack. IT staff couldn’t keep up with the alert volume. Remediation cost: $25M+.
In each case, the tools worked. The signal fired. What failed was the capacity to act.
Beyond missed breaches, dark data drives longer attacker dwell times (median of 11 days globally, per Mandiant’s M-Trends 2025), accelerates analyst burnout and turnover, creates regulatory exposure, and wastes billions in redundant triage cycles.
The path forward: match intelligence scale with response scale
The dark data problem didn’t emerge because CTI failed. It emerged because intelligence volume outgrew the manual processes built to handle it. Solving it requires closing the gap from both directions: reducing the volume of intelligence that needs human attention, and making it faster to act on the intelligence that does.
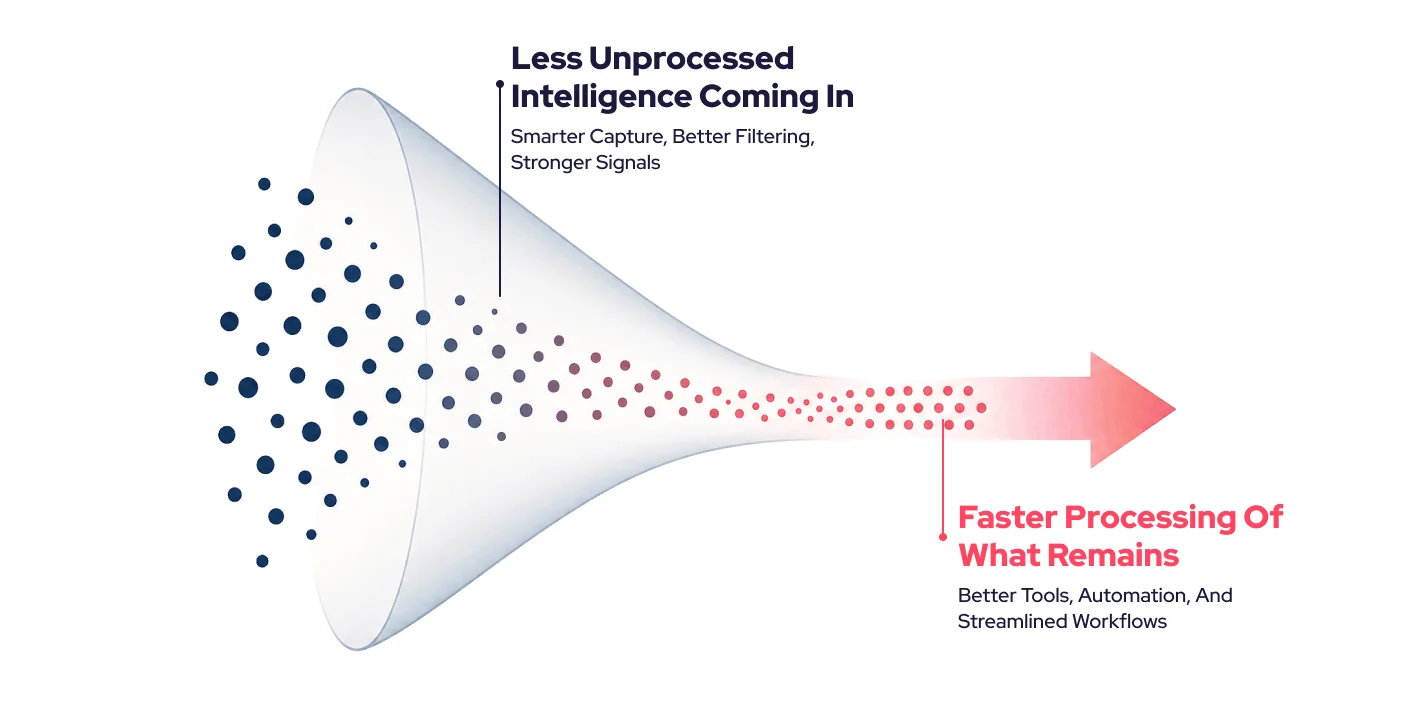
We reduce the volume of intelligence that needs human attention, and make it faster to act on the intelligence that does
Our paper breaks down exactly how dark data accumulates, what it costs organizations, and the approaches that are working to close the gap, including agentic AI workflows that handle detection and triage autonomously, and new integration standards like MCP that make intelligence accessible through natural language instead of console-hopping.
You can read the full whitepaper here

Table Of Content
Related Articles

Dark Web Profile: Section9 Ransomware


Dark Web Profile: ExfilSquad
Jul 28, 2026



