Mar 10, 2026

Jun 25, 2026
7 Mins Read
Table Of Content
Data Masking Definition
Types of Data Masking
Data Masking Techniques
Data Masking vs Encryption vs Tokenization
Benefits of Data Masking
Data Masking Use Cases
Compliance: GDPR, HIPAA, CCPA, and ISO 27001
When Unmasked Data Ends Up on the Dark Web?
How SOCRadar Threat Intelligence Detects Exposed Sensitive Data?
Frequently Asked Questions
Related Articles

SMS Bombing

Dark Web Monitoring
Feb 19, 2026

Dark Web
Jan 31, 2026

Threat Actors
Jan 08, 2026

Indicators of Compromise (IoCs)
Jan 31, 2026

What is Data Masking? Techniques, Types, and Compliance Guide
Data masking is a data security technique that replaces sensitive data with realistic but fictitious values, protecting personally identifiable information (PII) and other sensitive data in environments where production data is not necessary. Development teams need realistic data to test applications. Analytics teams need data to build models. Third-party vendors need data to do their work. Data masking allows all of this to happen without exposing real personal information.
When unmasked data finds its way into non-production environments, the consequences can be significant. Improperly protected development databases have repeatedly appeared in Dark Web data leak markets, exposing customer data that organizations assumed was safe because it was not in the production system.
Data Masking Definition
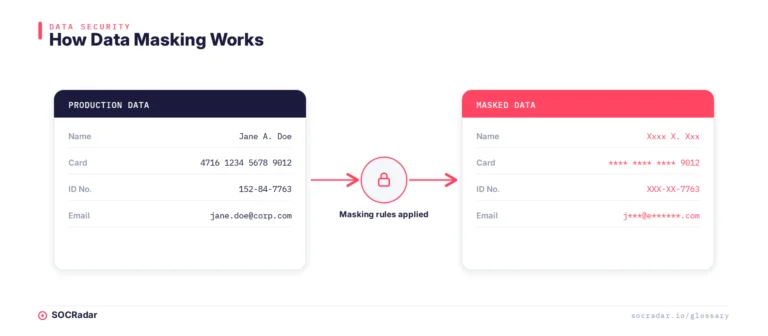
Data masking, also called data obfuscation or data anonymization in some contexts, is the process of creating a structurally similar but inauthentic version of an organization’s data. The masked data preserves the format, referential integrity, and statistical distribution of the original dataset, making it usable for development, testing, and analytics, while replacing actual sensitive values with fabricated ones.
The key distinction from encryption is irreversibility by design: masked data is intended to be used as-is, without the ability to recover the original values. This makes it suitable for sharing with third parties and for use in environments with broader access.
Types of Data Masking
Static Data Masking (SDM)
The most common type. A copy of the production database is created with all sensitive values replaced before the copy is shared with developers, testers, or analysts. The masking happens once, at the point of copy creation.
Dynamic Data Masking (DDM)
Sensitive data is masked in real time at the query layer, depending on who is making the request. A database administrator querying a customer table might see full data, while a developer or analyst running the same query sees masked values. The production data is never changed.
On-the-Fly Masking
Similar to dynamic masking but applied during ETL (extract, transform, load) processes. Data is masked as it moves from production to non-production environments.
Deterministic Masking
The same input value always produces the same masked output, preserving referential integrity across tables. This is critical when test data must maintain consistent relationships across a relational database.
Format-Preserving Masking
The masked value maintains the same format as the original: a masked credit card number is still 16 digits in the correct grouping, a masked phone number is still in valid phone number format. This preserves compatibility with application validation rules.
Data Masking Techniques
| Technique | Description | Best For |
| Substitution | Replace with realistic fictitious data from a lookup table | Names, addresses, phone numbers |
| Shuffling | Rearrange values within a column across records | Ages, salary ranges |
| Nulling out | Replace with null or empty values | Fields not needed in non-production |
| Encryption | Replace with cipher text (reversible with key) | Cases where data may need to be recovered |
| Number variance | Add random variation within a range | Financial values where exact figures are not needed |
| Masking out | Replace part of the value with a fixed character | Card numbers shown as **** **** **** 1234 |
| Tokenization | Replace with a non-sensitive token that maps back to original in a secure vault | Payment processing environments |
| Pseudonymization | Replace with consistent pseudonyms | Analytics where tracking individual behavior matters but real identity does not |
Data Masking vs Encryption vs Tokenization
These three techniques are often confused but serve different purposes.
Encryption is reversible. With the correct key, the original data can be recovered. It is appropriate for protecting data in transit or at rest when the data needs to be used in its original form.
Tokenization replaces sensitive data with a token. A secure vault maps the token back to the original value. The original data exists in the vault. Tokenization is common in payment processing.
Data masking is designed to be irreversible. The original data cannot be recovered from the masked value. This makes it more appropriate for development and testing environments where real data should never be needed.
When organizations need to share data with a third party for testing or analysis and do not need to recover the original values, data masking is the appropriate choice. When they need the ability to verify original values or process real transactions, tokenization or encryption is more suitable.
Benefits of Data Masking
PII protection
Masked data in non-production environments cannot expose real customer information if a developer laptop is stolen or a test environment is compromised.
Breach risk reduction
Development and testing environments typically have weaker access controls than production systems. Masking eliminates the risk that a breach of a non-production environment exposes real customer data.
GDPR and privacy compliance
Sharing real personal data with developers or third parties requires a legal basis under GDPR and similar regulations. Masked data does not constitute personal data and can be shared without those constraints.
Realistic test data
Unlike synthetic data generated from scratch, masked data preserves the statistical distribution and relational structure of the production dataset, making tests more representative.
Data Masking Use Cases
Development teams use masked data to test new features and bug fixes against realistic datasets without touching real customer information. QA testing environments run integration and performance tests using masked production data volumes. Analytics and reporting teams model on masked datasets. Third-party vendors given access to data for support or development work with masked copies. Cloud migration projects use masked data to validate the target environment before cutover.
Compliance: GDPR, HIPAA, CCPA, and ISO 27001
GDPR requires that personal data be processed with a lawful basis. Properly masked data that cannot be re-identified may fall outside GDPR scope, simplifying compliance for non-production environments.
HIPAA recognizes two methods for de-identifying protected health information (PHI): the Safe Harbor method, which requires removal of 18 specific identifiers, and the Expert Determination method. Data masking can be designed to satisfy the Safe Harbor requirements.
CCPA requires organizations to protect personal information and grant consumers rights over their data. Masked data reduces the inventory of personal data requiring active protection.
ISO 27001 Annex A controls include requirements for secure handling of test data, explicitly discouraging the use of real personal information in development and test environments.
When Unmasked Data Ends Up on the Dark Web?
Dark Web data leak markets regularly contain datasets that originated from non-production environments. Development databases with real customer data, backup files with PII, and test systems with real credentials are a recurring source of leaked data, not because the production systems were breached, but because non-production environments with weaker controls were targeted or accidentally exposed.
The pattern is consistent: real data used in a lower-security context leaks. Data masking closes this gap at the source by ensuring that non-production copies never contain real sensitive values.
How SOCRadar Threat Intelligence Detects Exposed Sensitive Data?
SOCRadar’s Advanced Dark Web Monitoring identifies when an organization’s data, including PII from development environments, appears on Dark Web markets or in data breach collections. When masked data policies fail or are not applied consistently, this monitoring provides early warning before the organization discovers the leak through a customer complaint or regulatory notification.
Frequently Asked Questions
What is data masking?
Data masking replaces sensitive data with realistic but fictitious values, protecting PII and other sensitive information in development, testing, and analytics environments.
Data masking vs encryption: which should I use?
Use encryption when you need to recover the original values. Use data masking when you do not need the original values and want to permanently protect sensitive data in non-production environments.
Is data masking the same as anonymization?
They overlap in intent but differ in method. Anonymization aims to make data impossible to re-identify. Data masking specifically replaces values with fictitious alternatives. Both are approaches to protecting personal data outside production contexts.