


Mar 10, 2026

Jan 31, 2026
5 Mins Read
Apr 17, 2026
Table Of Content
Related Articles

SMS Bombing

Dark Web Monitoring
Feb 19, 2026

Dark Web
Jan 31, 2026

Threat Actors
Jan 08, 2026

Indicators of Compromise (IoCs)
Jan 31, 2026

What is Deep Web?
Think about your daily internet routine. You check email, scroll through social media, maybe read some news. But here’s something most people don’t realize: you’re only seeing about 4% of what’s actually out there. The rest? It’s hiding in plain sight.
This hidden majority is called the deep web, and if you work in cybersecurity, understanding it isn’t optional anymore. It’s where your organization’s most sensitive data lives, and increasingly, it’s where threats emerge before they hit your radar.
What Exactly Is the Deep Web?
Let’s clear something up right away. The deep web isn’t some shadowy underworld. It’s just content that Google and other search engines can’t find. Your Gmail inbox? Deep web. Your online banking dashboard? Deep web. That company SharePoint site you complained about this morning? Definitely deep web.
Here’s the thing: search engines can only index what they can reach. Anything behind a login screen, tucked inside a database, or dynamically generated on-demand stays invisible to them. And that’s actually by design.
The numbers tell an interesting story. Researchers estimate the deep web is somewhere between 400 to 500 times larger than the surface web. We’re talking about an absolutely massive amount of information—medical records, legal filings, academic research, proprietary business data. Most of it perfectly legitimate, all of it intentionally kept private.
Why Can’t Search Engines See It?
Search engines rely on crawlers—basically automated programs that bounce around the web, following links and cataloging what they find. Simple enough. But these crawlers hit walls constantly.
Authentication stops them cold. No login credentials? No access. CAPTCHAs do the same thing, deliberately filtering out bots from humans. Then there’s the technical side. Database-driven websites generate pages on the fly based on what you’re searching for. These pages don’t exist until you create them, so there’s nothing for a crawler to find beforehand.
Website administrators also have control here. A simple robots.txt file can tell search engines “stay out,” and they comply. Privacy by design, really.
What You’ll Actually Find There
Most of us use deep web resources daily without thinking twice. Email platforms operate entirely in this space. Your messages stay private, searchable only by you within your account.
Banking portals are another obvious example. Can you imagine if your transaction history showed up in Google results? The authentication layer keeping that information private is what makes it part of the deep web.
Then you’ve got subscription databases—academic journals, market intelligence platforms, professional research tools. Paywalls keep them out of public search results. Corporate intranets, cloud storage, government records systems, patient health portals—all deep web territory.
Deep Web vs. Dark Web: Why the Confusion?
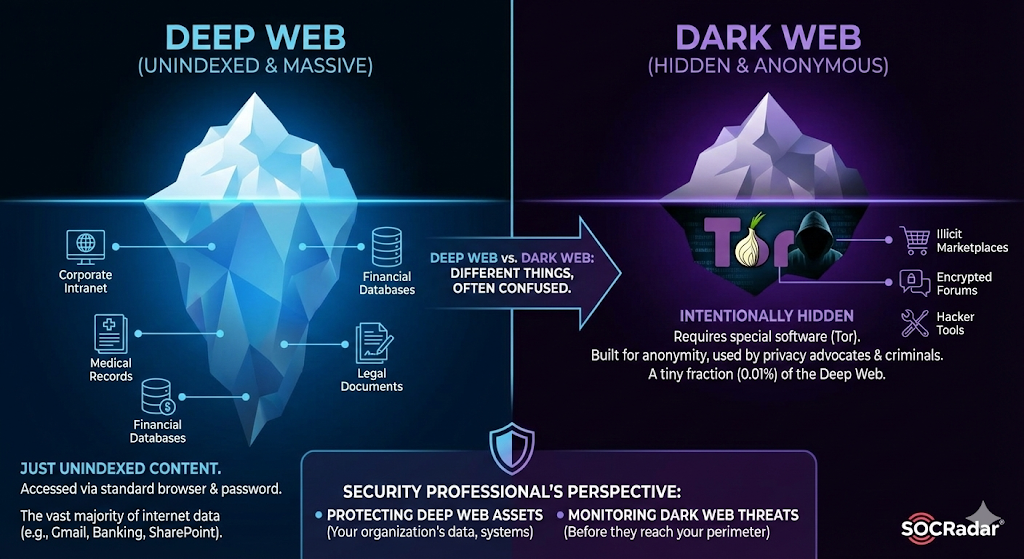
Here’s where things get messy in public perception. People use “deep web” and “dark web” interchangeably, but they’re describing completely different things.
The deep web is just unindexed content. Normal browser, normal internet connection, usually just a password standing between you and it.
The dark web is intentionally hidden, requiring special software like Tor to access. It’s built for anonymity, which attracts both privacy advocates and, yes, criminal operations. But here’s the scale: the dark web represents maybe 0.01% of the deep web. Tiny fraction, massive reputation.
For those of us in security, the distinction matters significantly. You’re protecting deep web assets every day—your organization’s data, systems, communications. But you’re also watching for threats that might originate from the dark web before they reach your perimeter.
The Security Challenge Nobody Talks About
Traditional security tools give you decent visibility into surface web threats. Phishing domains, malicious websites, drive-by downloads—these get flagged relatively quickly. But what about credential dumps sitting in compromised databases? Data leaked from your systems appearing in unexpected corners of the internet?
That’s where things get complicated. Cybercriminals don’t just operate in one space. They steal credentials from deep web breaches, sell them on dark web marketplaces, then use them to compromise more deep web resources. It’s a cycle, and breaking it requires visibility across all these layers.
SOCRadar’s Extended Threat Intelligence was built specifically for this problem. Instead of waiting for threats to reach your network, it monitors where they actually develop—across deep web forums, dark web marketplaces, compromised databases, even paste sites where attackers dump stolen data.
Think about your typical breach scenario. Credentials get compromised months before they’re used. Data gets exfiltrated and sits dormant before someone monetizes it. By the time traditional tools detect the threat, you’re already responding to an incident. But what if you caught it earlier?
Building Real Protection
Multi-factor authentication isn’t negotiable anymore. Passwords alone won’t cut it, not when credential databases leak constantly. Layer your authentication, and suddenly compromised passwords become significantly less useful to attackers.
Encryption matters both ways—data moving across networks and data sitting in storage. If someone intercepts it or accesses it without authorization, encryption renders it useless.
Regular audits catch the stuff that slips through. Access controls drift over time. Former employees retain permissions they shouldn’t have. Systems develop vulnerabilities. Consistent review cycles prevent these gaps from becoming incidents.
But here’s what really makes the difference: knowing what’s happening outside your walls. Employee credentials appearing in credential dumps. Company data showing up on file-sharing platforms. Brand impersonation sites collecting customer information.










